Extend GraphQL API
Learn how to extend the Page Builder-related GraphQL types and operations.
- how to extend the Page Builder-related GraphQL types and operations
webiny watch command to continuously deploy application code changes into the cloud and instantly see them in action. For quick (manual) testing, you can use the built-in API Playground.Adding New Page Fields
In this example, we’ll add a new special boolean field to the central PbPage GraphQL type. As the name suggests, the field will tell us whether a page is special or not.
It all starts with the GraphQLSchemaPlugin  , which we’ll need to register within our GraphQL API’s application code. Once we have that, optionally, we might want to register the
, which we’ll need to register within our GraphQL API’s application code. Once we have that, optionally, we might want to register the IndexPageDataPlugin plugin, which will enable us to get the value of the new special field also while listing pages.
import { GraphQLSchemaPlugin } from "@webiny/handler-graphql/plugins";
import { IndexPageDataPlugin } from "@webiny/api-page-builder/plugins/IndexPageDataPlugin";
import { Page } from "@webiny/api-page-builder/types";
// Make sure to import the `Context` interface and pass it to the `GraphQLSchemaPlugin`
// plugin. Apart from making your application code type-safe, it will also make the
// interaction with the `context` object significantly easier.
import { Context } from "~/types";
interface ExtendedPage extends Page {
special: boolean;
}
export default [
// Adding a new `special` field to the PbPage type consists of three steps:
// 1. Extend the fundamental `PbPage` type.
// 2. Extend the `PbPageListItem` type which is used when listing pages.
// 3. In order to update the field, we also need to extend the `PbUpdatePageInput` input.
new GraphQLSchemaPlugin<Context>({
typeDefs: /* GraphQL */ `
extend type PbPage {
special: Boolean
}
extend type PbPageListItem {
special: Boolean
}
extend input PbUpdatePageInput {
special: Boolean
}
`
}),
// This step is only required if you're using DynamoDB + ElasticSearch setup and you want
// to be able to get the value of the `special` field while listing pages.
// With this plugin, we ensure that the value of the `special` field is also stored in
// ElasticSearch, which is where the data is being retrieved from while listing pages.
new IndexPageDataPlugin<ExtendedPage>(({ data, page }) => {
// `data` represents the current page's data that will be stored in ElasticSearch.
// Let's modify it, by adding the value of the new `special` flag to it.
data.special = page.special;
})
];The code above can be placed in the api/graphql/src/plugins/pages.ts file, which doesn’t exist by default, so you will have to create it manually. Furthermore, once the file is created, make sure that it’s actually imported and registered in the api/graphql/src/index.ts entrypoint file.
With all the changes in place, we should be able to update an existing Page Builder page and mark it as special, with the following mutation:
mutation UpdatePage($id: ID!, $data: PbUpdatePageInput!) {
pageBuilder {
updatePage(id: $id, data: $data) {
data {
id
title
special
}
}
}
}For example:
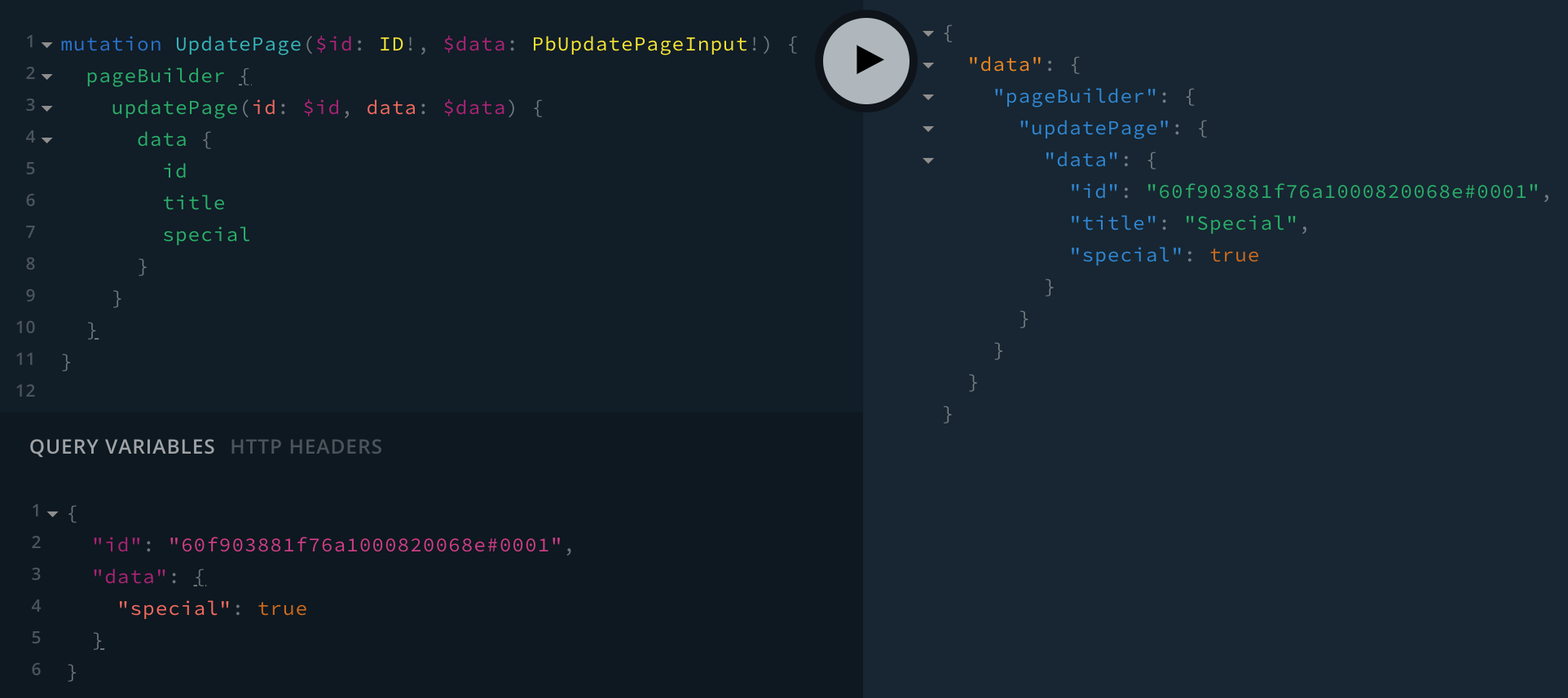 Marking an Existing Page as Special
Marking an Existing Page as SpecialRunning the above mutation should mark the page with the 60f903881f76a1000820068e#0001 ID as special, which we should be able to see afterwards while performing queries:
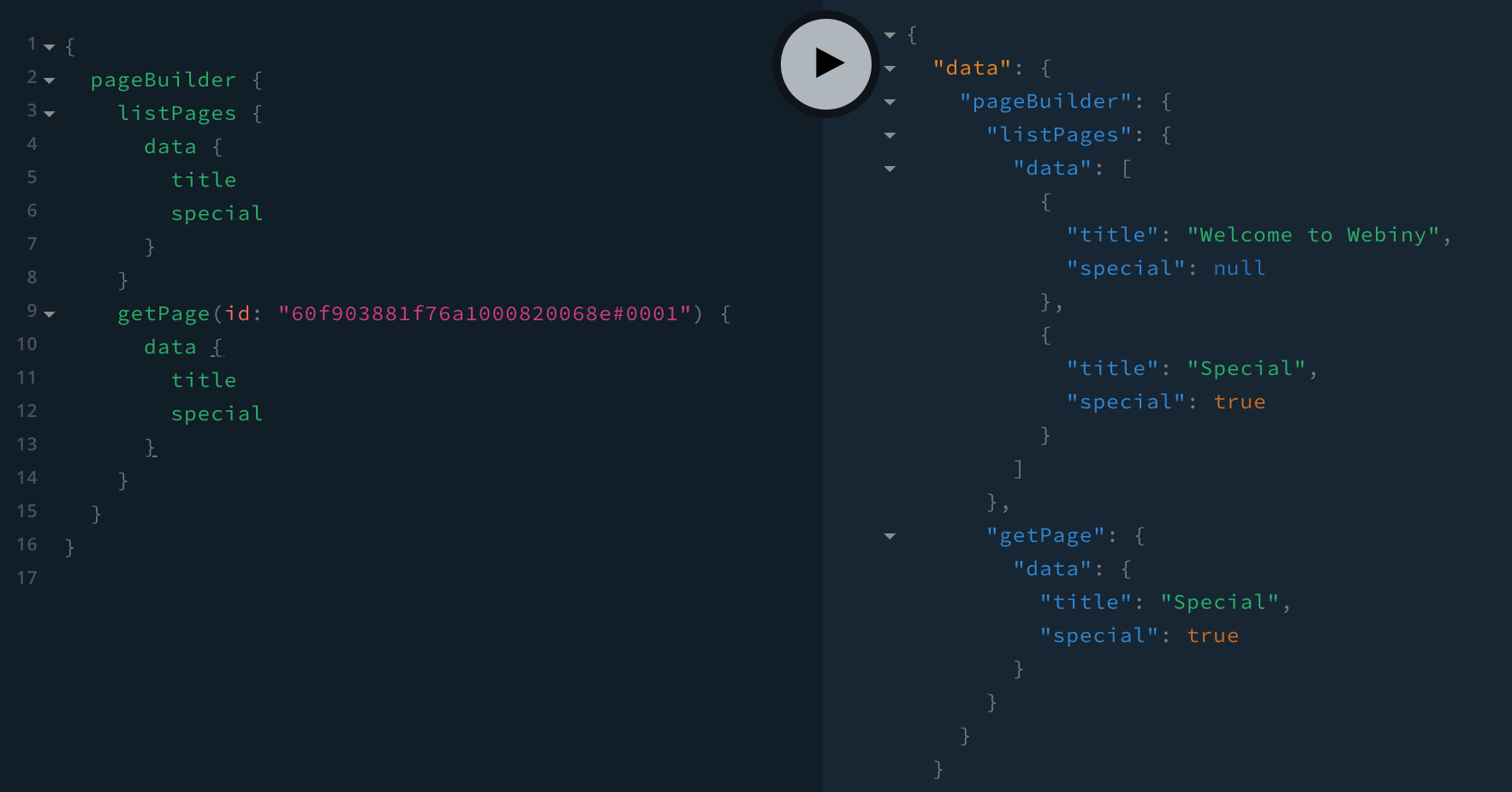 Querying Pages with the New Special Field Included in the Results
Querying Pages with the New Special Field Included in the ResultsModifying GraphQL Queries
If needed, existing pages-related GraphQL queries can be modified too.
Continuing from the previous example, let’s say we also wanted to be able to list special pages only. We can do that with the help of the SearchLatestPagesPlugin and SearchPublishedPagesPlugin plugins (both extending SearchPagesPlugin ):
import { GraphQLSchemaPlugin } from '@webiny/handler-graphql/plugins'import { IndexPageDataPlugin } from '@webiny/api-page-builder/plugins/IndexPageDataPlugin'import { Page } from '@webiny/api-page-builder/types'import { SearchLatestPagesPlugin } from '@webiny/api-page-builder/plugins/SearchLatestPagesPlugin'import { SearchPublishedPagesPlugin } from '@webiny/api-page-builder/plugins/SearchPublishedPagesPlugin'
// Make sure to import the `Context` interface and pass it to the `GraphQLSchemaPlugin`// plugin. Apart from making your application code type-safe, it will also make the// interaction with the `context` object significantly easier.import { Context } from '~/types'
interface ExtendedPage extends Page {special: boolean}
export default [// We can extend the `PbListPagesWhereInput` and `PbListPublishedPagesWhereInput`// types in order to enable filtering pages by the `special` field. Note that in order for this// to work, we'll also need `SearchLatestPagesPlugin` and `SearchLatestPagesPlugin` (see below).new GraphQLSchemaPlugin<Context>({ typeDefs: /* GraphQL */ ` extend type PbPage { special: Boolean }
extend type PbPageListItem { special: Boolean }
extend input PbUpdatePageInput { special: Boolean }
extend input PbListPagesWhereInput { special: Boolean }
extend input PbListPublishedPagesWhereInput { special: Boolean } `,}),
new IndexPageDataPlugin<ExtendedPage>(({ data, page }) => { data.special = page.special}),
// Query modifiers must be applied to both latest and published pages queries.// Both of these make sure that if the GraphQL query contains `special: true` in the `where`// input, that the ElasticSearch query is modified accordingly.new SearchLatestPagesPlugin({ modifyQuery({ query, args }) { if (args.where && args.where.special) { query.must.push({ term: { special: true, }, }) } },}),new SearchPublishedPagesPlugin({ modifyQuery({ query, args }) { if (args.where && args.where.special) { query.must.push({ term: { special: true, }, }) } },}),]With all the changes in place, we should be able to run the following GraphQL query:
query ListSpecialPages {
pageBuilder {
listPages(where: { special: true }) {
data {
title
special
}
error {
data
message
code
}
}
}
}For example:
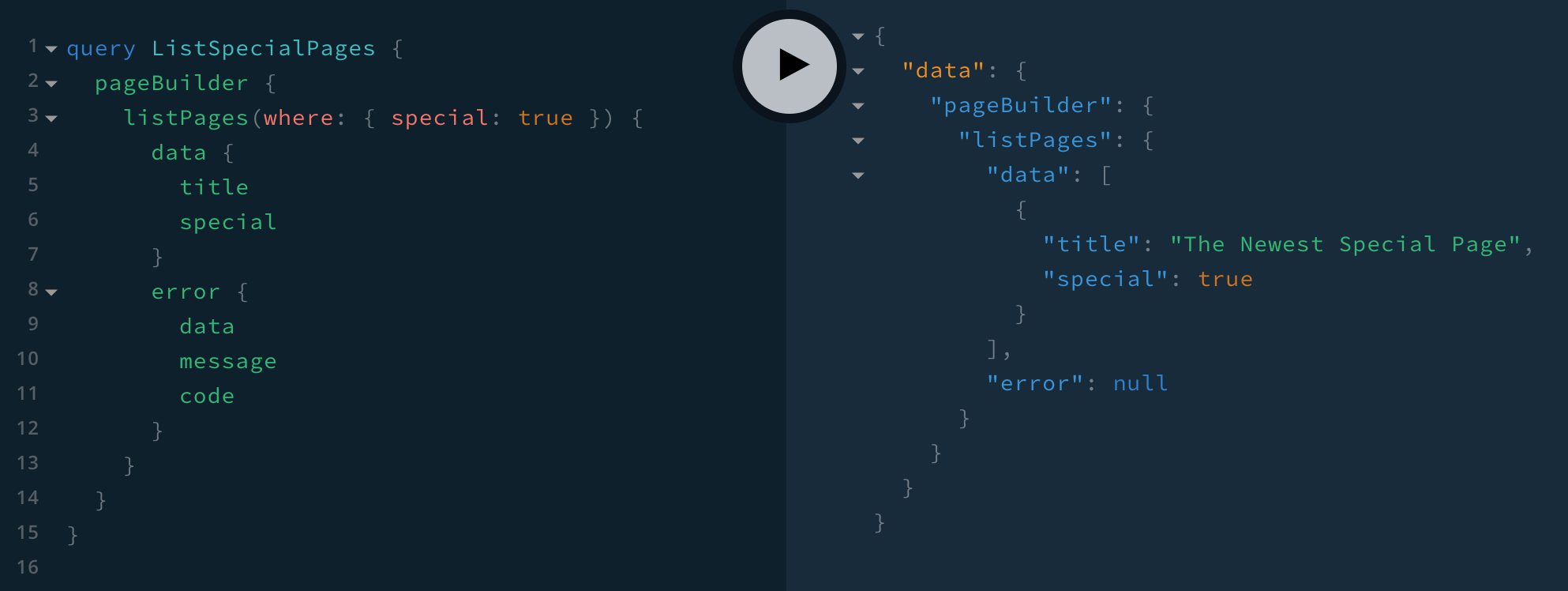 Listing Special Pages
Listing Special PagesNote that because we’ve created both the SearchLatestPagesPlugin and SearchPublishedPagesPlugin plugins, we can also apply the same special: true filter within the listPublishedPages GraphQL query.
The difference between the listPages and listPublishedPages is in the returned results. The former will always return latest revisions of a pages, which is more useful while listing pages inside the Admin Area application. The latter always returns published revisions of pages, which is more suitable for public applications and websites.
Custom GraphQL Mutations
Let’s say we wanted to extend our GraphQL schema with the custom duplicatePage mutation, which, as the name suggests, would enable us to make copies of pages.
We can achieve this with a single GraphQLSchemaPlugin plugin.
import { GraphQLSchemaPlugin } from "@webiny/handler-graphql/plugins";
import { PbContext } from "@webiny/api-page-builder/types";
import { Response, ErrorResponse, NotFoundResponse } from "@webiny/handler-graphql/responses";
// Make sure to import the `Context` interface and pass it to the `GraphQLSchemaPlugin`
// plugin. Apart from making your application code type-safe, it will also make the
// interaction with the `context` object significantly easier.
import { Context } from "~/types";
export default [
new GraphQLSchemaPlugin<Context>({
// Extend the `PbMutation` type with the `duplicatePage` mutation.
typeDefs: /* GraphQL */ `
extend type PbMutation {
# Creates a copy of the provided page.
duplicatePage(id: ID!): PbPageResponse
}
`,
// In order for the `duplicatePage` to work, we also need to create a resolver function.
resolvers: {
PbMutation: {
duplicatePage: async (_, args: { id: string }, context: PbContext) => {
// Retrieve the original page. If it doesn't exist, immediately exit.
const pageToDuplicate = await context.pageBuilder.pages.get(args.id);
if (!pageToDuplicate) {
return new NotFoundResponse("Page not found.");
}
try {
// We only need the `id` of the newly created page.
const newPage = await context.pageBuilder.pages.create(pageToDuplicate.category);
// Set data that will be assigned to the newly created page.
const data = {
title: `Copy of ${pageToDuplicate.title}`,
path: `${pageToDuplicate.path}-copy-${new Date().getTime()}`,
content: pageToDuplicate.content,
settings: pageToDuplicate.settings
};
// Finally, update the newly created page.
const updatedNewPage = await context.pageBuilder.pages.update(newPage.id, data);
return new Response(updatedNewPage);
} catch (e) {
return new ErrorResponse(e);
}
}
}
}
})
];The code above can be placed in the api/graphql/src/plugins/pages.ts file, which doesn’t exist by default, so you will have to create it manually. Furthermore, once the file is created, make sure that it’s actually imported and registered in the api/graphql/src/index.ts entrypoint file.
With all the changes in place, we should be able to run the following GraphQL mutation:
mutation DuplicatePage($id: ID!) {
pageBuilder {
duplicatePage(id: $id) {
data {
id
title
path
}
}
}
}For example:
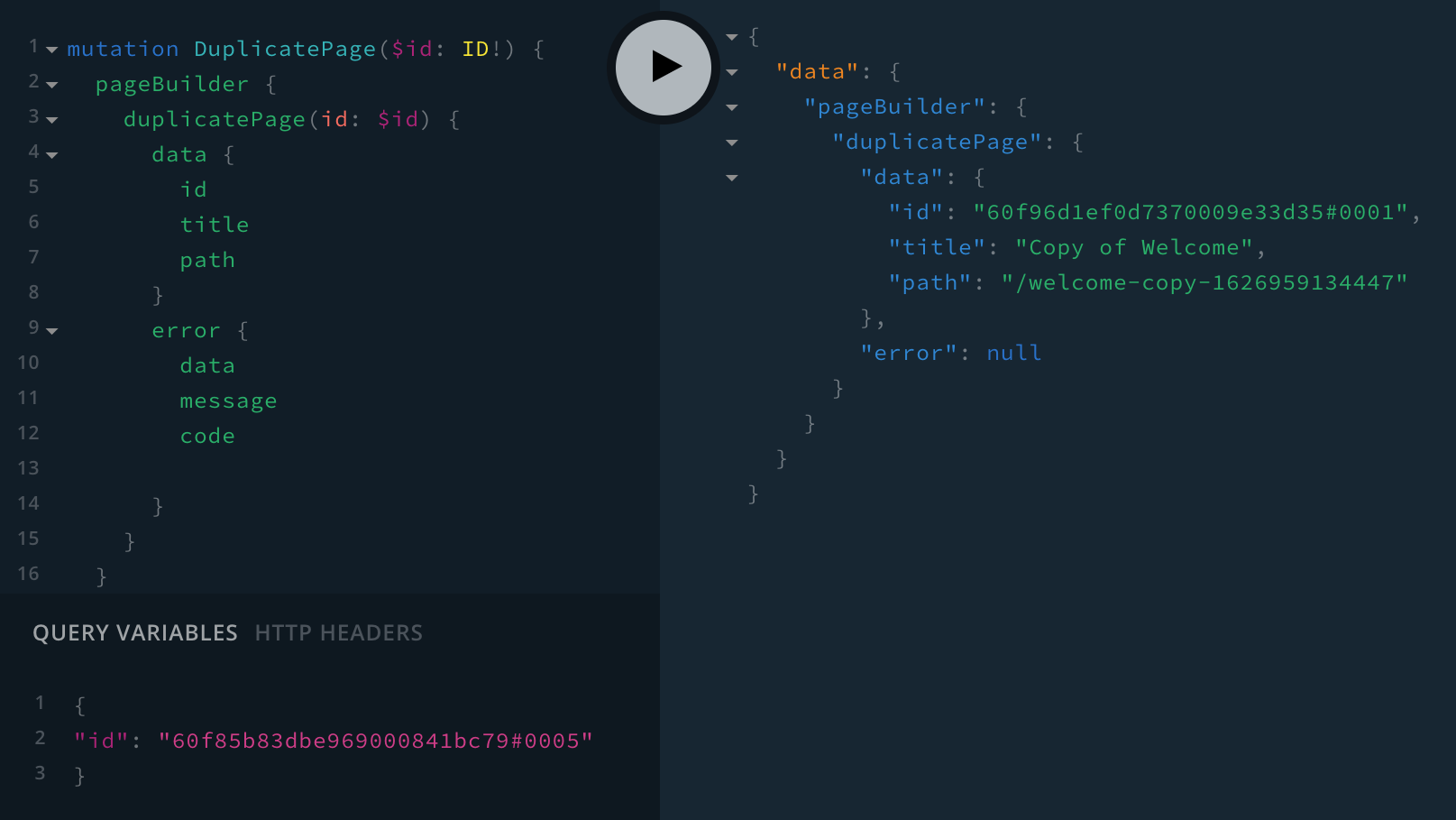 Duplicating an Existing Page
Duplicating an Existing PageAfter the mutation has been executed, we should be able to see the created copy in the list of pages:
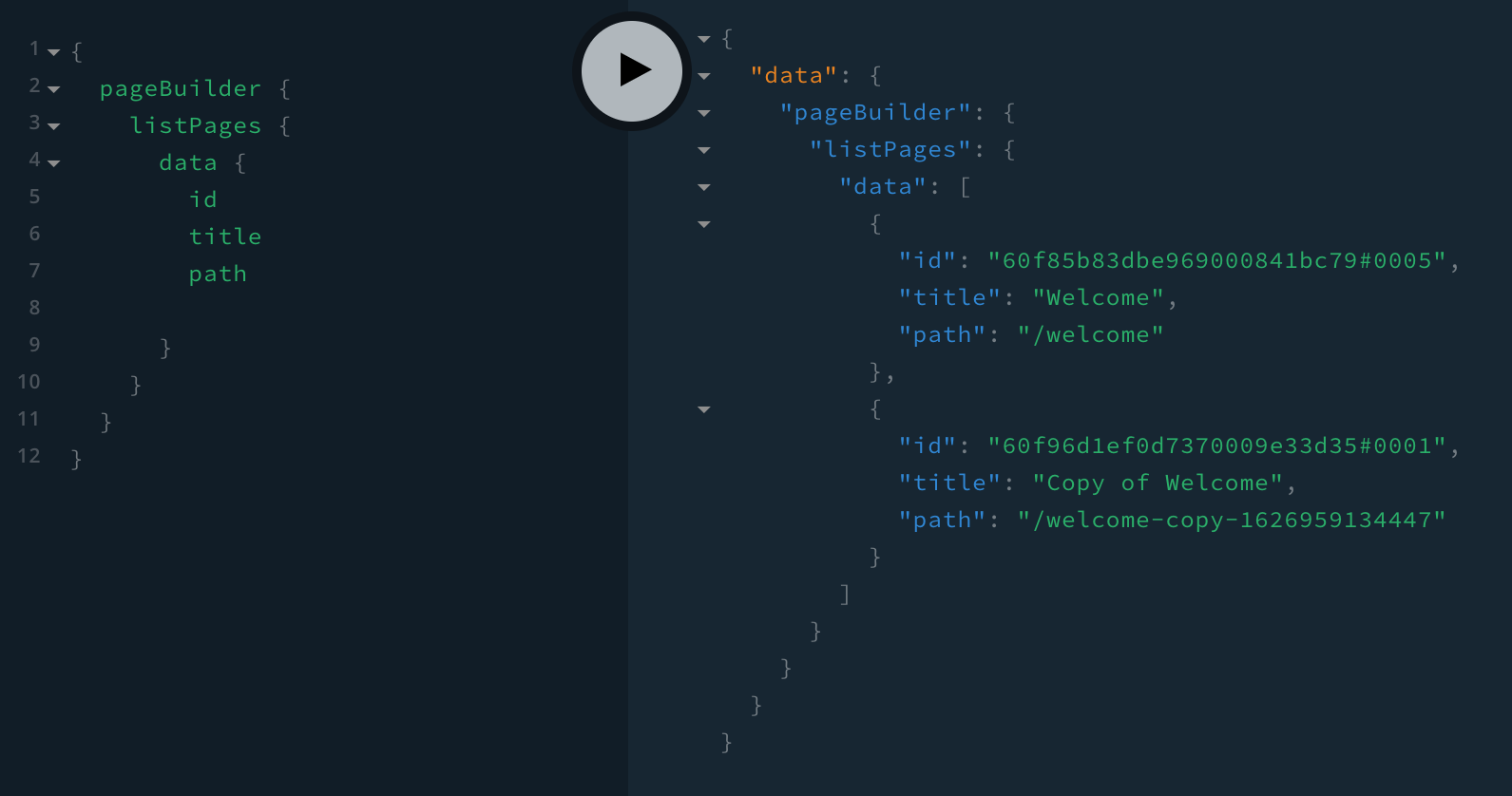 Listing Pages After A Copy Has Been Created
Listing Pages After A Copy Has Been CreatedFAQ
What Is the context Object and Where Are All of Its Properties Coming From?
In the shown examples, you may have noticed we were using the context object in GraphQL resolver functions. This object contains multiple different properties, mainly being defined from different Webiny applications that were imported in the GraphQL API’s api/graphql/src/index.ts entrypoint file.
That’s why, for example, we were able to utilize the context.pageBuilder.pages.get and context.pageBuilder.pages.update methods, in the Custom Mutations section.
For easier discovery and type safety, we suggest a type is always assigned to the context object in your GraphQL resolver functions.